我们知道,linux系统在读取数据的时候,并不是直接从磁盘或者网卡读取到用户进程中的,其中会经历过从设备到内核缓冲区,再由内核缓冲区到用户缓冲区的过程,这个过程最早是由CPU进行的,后来设计了DMA设备在这个过程中解放了CPU,但是仍然不能完全避免CPU的操作
低效的IO系统
在不存在DMA设备的时候,读取磁盘的过程大致如下所示:
可以看到,一次IO的过程涉及到四次内核态与用户态的切换,以及四次拷贝的过程,两次拷贝分别是指:
CPU将数据从磁盘拷贝到内核缓冲区
CPU将数据从内核缓冲区拷贝到用户缓冲区
CPU将数据从用户缓冲区拷贝到内核缓冲区
CPU将数据从内核缓冲区写入到网卡
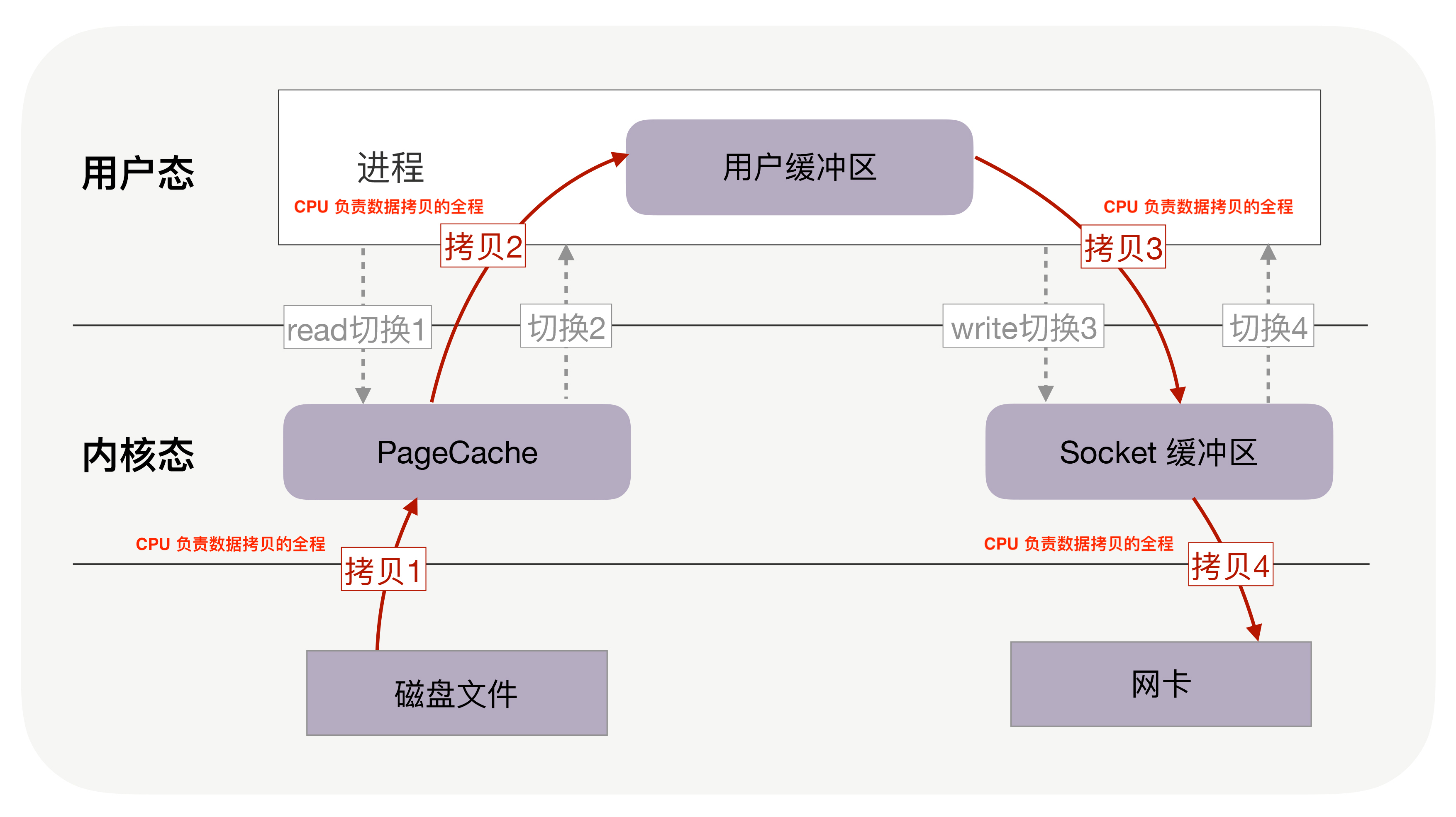
可以看到,CPU在这个过程中扮演了将数据搬运到指定区域的角色,这意味着在进行IO的这段时间里,CPU无法空闲,需要执行数据拷贝的操作,在一次完整的IO中,竟然需要拷贝四次数据,切换四次状态,这样的操作太多了,会严重影响IO的效率,同时CPU被占用又会严重影响系统的效率。
DMA技术解放CPU
后来研发了一种新的技术叫做直接内存访问(DMA),旨在解放文件传输过程中的CPU,减少CPU的占用。
DMA技术本质上是在设备上面增加一个独立的芯片,这个芯片能够承担数据传输的作用,这样当用户进程发起文件读取的需求时,不再由CPU进行数据拷贝,而是CPU告知DMA控制器(DMAC)需要传输的数据的起点和长度,此时CPU可以区执行其它的工作,再由DMA芯片将数据传输到内核缓冲区,数据传输完成后,DMA控制器会发起一个中断信号,告知CPU数据传输完成,CPU再回来继续执行这部分内容。
然而DMA技术也有它的问题,它是用于设备间的数据交互的加速,换句话说,对于用户态与内核态之间的数据传输,仍然需要CPU来完成
当我们使用DMA技术的时候,一个简单的读取磁盘中的文件并通过网络发送的流程如下图所示,我们可以看到,即使在这样一个过程下,我们也只是节省了两次CPU进行数据拷贝的时间。
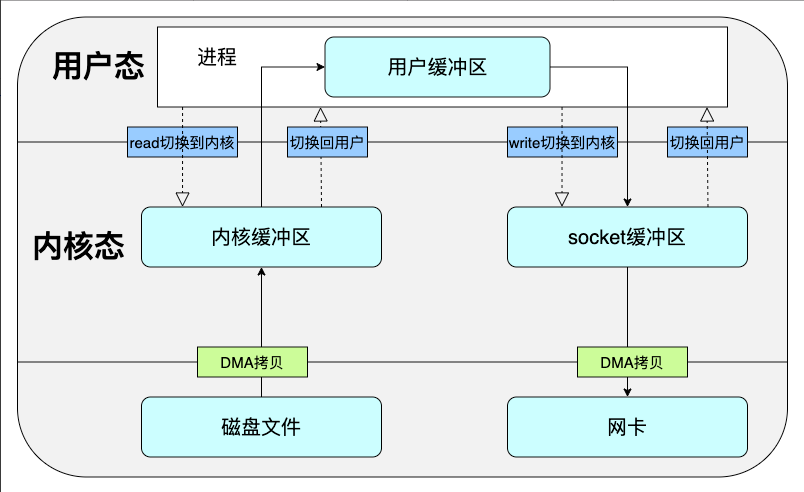
这个过程并不简洁,它包含了两次系统调用以及两次CPU执行的数据拷贝,这个过程中,我们为了将磁盘的数据发送到网络上,将一份数据拷贝了四次。
显然,如果我们希望降低IO时性能的损耗,就应该从降低系统调用次数以及CPU数据拷贝次数的角度来进行。
更高效的文件传输方式
为了优化系统IO的能力,linux在高版本内核中提供了两个关键命令:mmap和sendfile。
mmap:它取代了read命令的作用,将内核缓冲区的数据直接映射到了用户内存中,减少了一次CPU将数据从内核缓冲区转运到用户缓冲区的过程。sendfile:sendfile比起上一个命令要更进一步,它允许用户直接传入起始的文件描述符和目的文件描述符,直接在两个文件之间进行搬运,将read和write的作用集中到了一个命令上面。
mmap
我们能够意识到,read命令有一步把内核缓冲区的数据拷贝到用户缓冲区,这一步是由CPU来完成的,但这一步不是必须的,我们完全可以节省这一步操作,mmap命令的作用就在于此,一个简单的mmap调用流程如下所示:
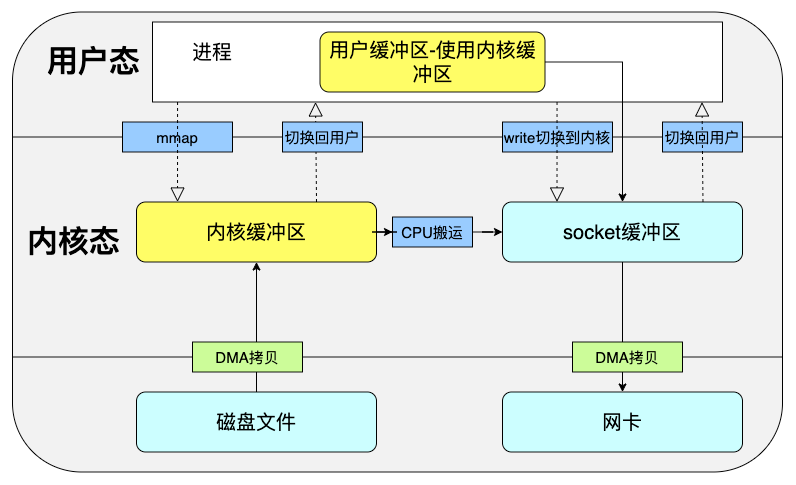
用户进程调用
mmap命令之后,DMA将磁盘数据拷贝到内核缓冲区,linux将内核缓冲区映射到了用户内存,使得用户进程可以直接操作内核缓冲区的内存。用户进程调用
write命令,CPU将数据从内核缓冲区拷贝到socket缓冲区DMA将数据从socket缓冲区写入到网卡
我们可以看到,在这个过程中,我们仍然执行了两次系统调用,但是减少了一次将数据拷贝到用户缓冲区的操作,这仍然是有优化的空间的。
sendfile
linux内核在2.1版本中提供了一个专门用于发送文件的系统命令,sendfile,它可以直接将某个文件在从源文件描述符写入目的文件描述符,这意味着又减少了一次系统调用的成本。
一个简单的sendfile命令的过程如下所示:
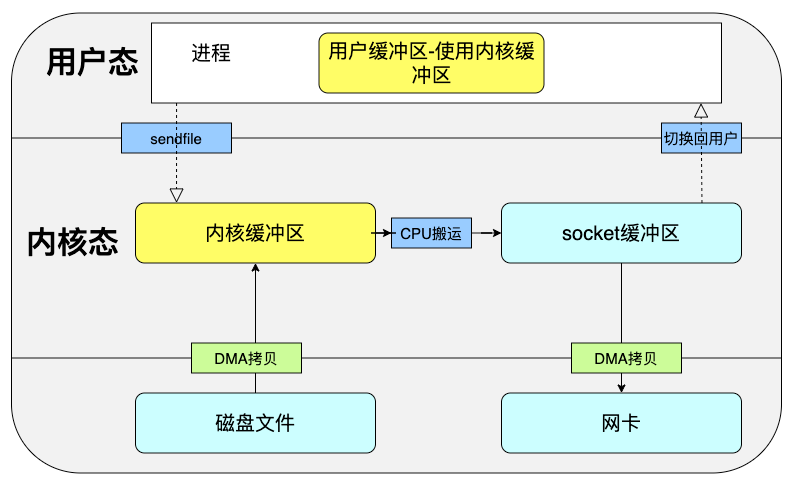
当然,这并不是没有更进一步优化的可能,如果网卡能够支持SG-DMA技术,那么可以通过SG-DMA直接从内核缓冲区拷贝到网卡中。
所谓零拷贝
以上就是所谓的零拷贝技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
事实上,我们常说的零拷贝,就止步于mmap这个层级,通过减少一次CPU的数据拷贝,能够大幅提升IO的效率,也就是说,在没有更高级的硬件的基础上,从内核缓冲区到网卡的CPU拷贝是无法避免的。