date: '2023-04-11'
categories:
- 搜索
- elasticsearch
tags:
- 分页查询
- 搜索
- elasticsearch
一、前言
我们通常对检索到的内容的长度是有限制的,这个限制一方面是为了保证结果的高速返回以减少对用户体验的影响,另一方面,也是为了保护服务器,大量数据的同时返回极有可能回打垮我们的服务。既然返回的数据不完整,那么为了用户能够获取到完整的信息,就需要给用户一个入口能够获取剩余的内容,这就是分页功能。
我们常见的分页有如下两种形式:
按页码分页:
滑动分页(加载更多或向上滑动或向下滑动)

这两种模式对于用户而言的区别在于能否自由的跳转到想要去往的页码以及能否感知到总页数。
对于ElasticSearch来说,它提供的分页方案都是滑动分页的方案,也就是说ES对于页码式的分页场景的支持性很差,甚至可以说没有支持。
二、ElasticSearch的分页方案
from+size
一个简单的from+size的请求如下所示
{
"from":1,
"size":100
}这个方式是利用了_id字段进行翻页查询,但是它要求你必须输入起始的id,且受到限制,from+size的值大于1万时会报错,这个值受到index.max_result_window这个参数的限制。这个参数可以进行调整,但是需要注意,它的性能并不好,深度翻页不仅响应时间会变长,也会影响集群本身的性能
{
"error": {
"root_cause": [
{
"type": "query_phase_execution_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "kibana_sample_data_flights",
"node": "YRQNOSQqS-GgSo1TSzlC8A",
"reason": {
"type": "query_phase_execution_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
]
},
"status": 500
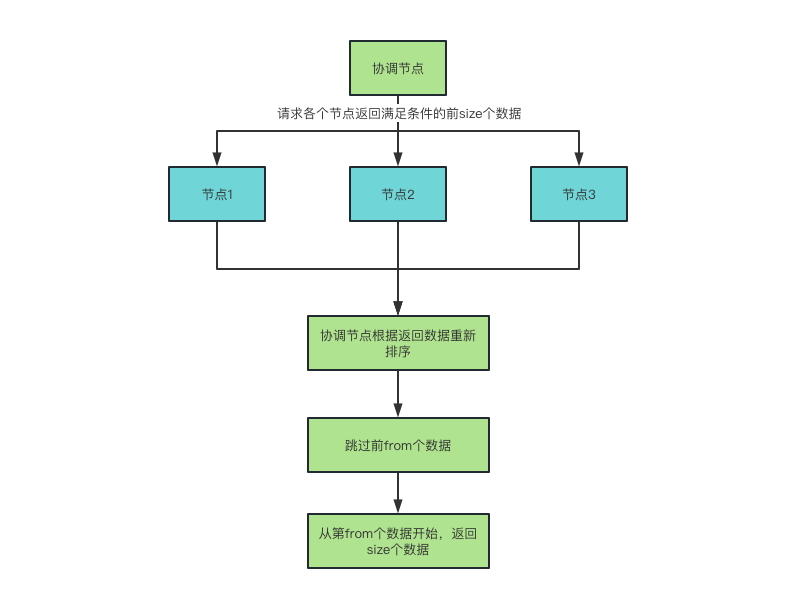
}from+size的方式获取数据的流程如下图所示,我们可以看到,对于任意的一次from+size请求来说,为了保证数据的准确性,实际上每个节点都返回了from+size个数据,最后在协调节点进行了数据的重排序以及跳过操作,随着from数值的不断增大,每个节点返回的数据量以及协调节点需要处理的数据量都是在成倍增长的。因此from+size在总数据量比较大的情况下最好不要使用。
search after
Search After和from+size的执行逻辑不同,Search After是基于游标的翻页逻辑,用户需要在检索的时候指定用于排序的字段,这样每个分片都能按照排序规则对结果进行排序,需要注意的是:排序的字段需要是唯一的,或者至少保证有一个排序字段是唯一的。
Search after的第一次请求的参数如下所示:
{
"size":10,
"query":{
"bool":{
"filter":[
{
"term":{
"operator":{
"value":"XXXXX"
}
}
}
]
}
},
"sort":[
{
"time":{
"order":"desc"
}
}
]
}请求成功之后,一个简单的响应如下所示:
{
"took" : 78,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 295,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "XXXXX",
"_type" : "_doc",
"_id" : "oiiAaocBG444_bgssK3d",
"_score" : null,
"_source" : {
},
"sort" : [
1
]
}
]
}
}
在响应的文档中会包含一个特殊的字段,sort,这个字段的格式是Object[],我们需要在下一次请求的search after字段中传入最后一个文档的sort字段。
{
"size":100,
"sort":[
{
"time":{
"order":"desc"
}
}
],
"search_after":[
123
]
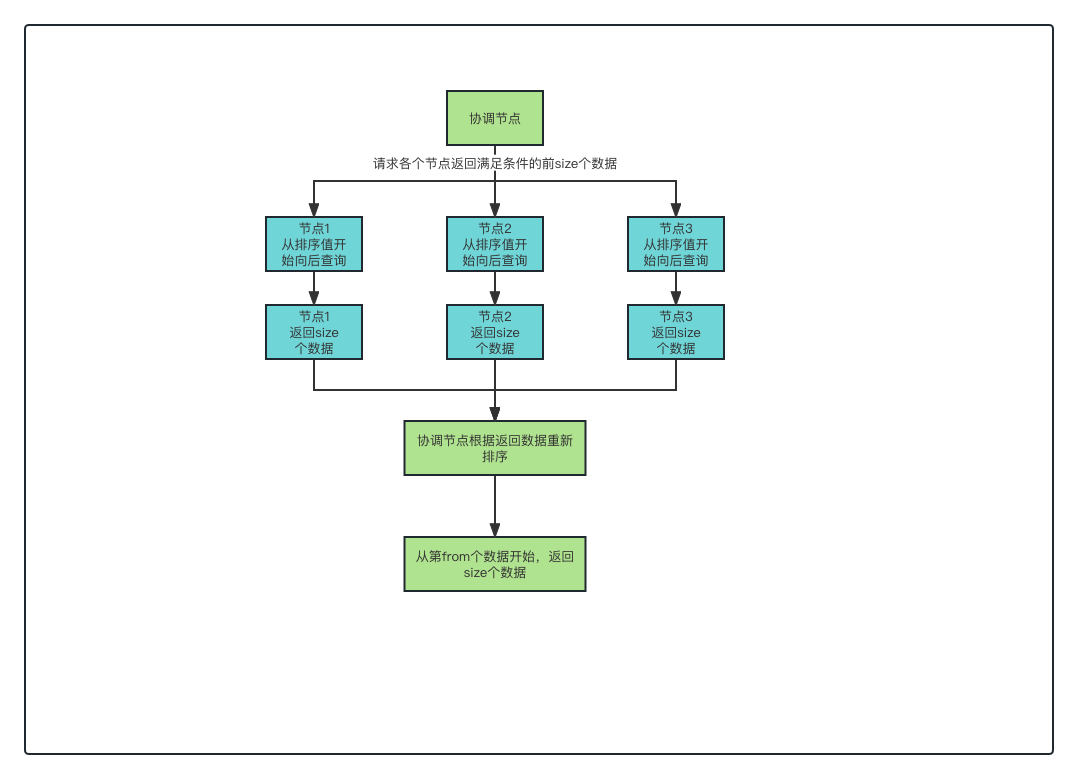
}因为这个字段是排序字段的值,这意味着每个分片都可以自行跳过需要跳过的文档,返回指定数量的文档, 对比from+size的格式,每个分片需要返回的数量大大减少,降低协调节点的压力,同时也能够更充分的利用索引的性能。
search afer的执行流程如下所示:
总结
ElasticSearch目前常用的两种分页查询就是from+size和search after,其中from+size更多的是利用ES自己的_id字段,而search after则更多的是利用记录自己的字段的有序性。
对比起来,search after的性能相对要更好一些,但是无论是from+size还是search after都无法做到随机跳转分页,尤其是当使用量比较大的时候,他们要求使用者只能通过加载更多的形式来获取剩余的数据。